Starting of october that is week 10 brought something interesting,i
was introduced to Recommendation system by Dr. Sarabjot Singh Anand,
Co-Founder Sabudh Foundation ,Er. Niharika Arora ,Data Scientist at
Tatras Data and Er. Gurmukh Singh ,Trainee Data Scientist at Tatras
Data.
Recommender systems are one of the most successful and widespread application of machine learning technologies in business.You can apply recommender systems in scenarios where many users interact with many items.You can find large scale recommender systems in retail, video on demand, ormusic streaming.
In order to develop and maintain such systems, a company typically
needs a group of expensive data scientist and engineers. That is why
even large corporates such as BBC decided to outsource its recommendation services.
Machine learning algorithms in
recommender systems are typically classified into two categories —
content based and collaborative filtering methods although modern
recommenders combine both approaches. Content based methods are based on
similarity of item attributes and collaborative methods calculate
similarity from interactions. Below we discuss mostly collaborative
methods enabling users to discover new content dissimilar to items
viewed in the past.
Collaborative
methods work with the interaction matrix that can also be called rating
matrix in the rare case when users provide explicit rating of items.
The task of machine learning is to learn a function that predicts
utility of items to each user. Matrix is typically huge, very sparse and
most of values are missing.
The simplest algorithm computes
cosine or correlation similarity of rows (users) or columns (items) and
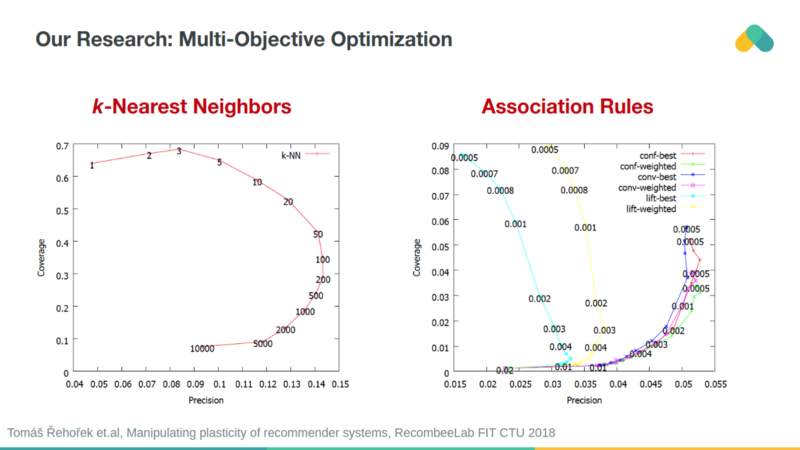
recommends items that k — nearest neighbors enjoyed.
Matrix factorization based methods
attempt to reduce dimensionality of the interaction matrix and
approximate it by two or more small matrices with k latent components.
Association
rules can also be used for recommendation. Items that are frequently
consumed together are connected with an edge in the graph. You can see
clusters of best sellers (densely connected items that almost everybody
interacted with) and small separated clusters of niche content.
EVALUATION OF RECOMMENDER SYSTEM
More
practical offline evaluation measure is recall or precision evaluating
percentage of correctly recommended items (out of recommended or
relevant items). DCG takes also the position into consideration assuming
that relevance of items logarithmically decreases.
The problem which we covered was Cold start problem in that
Sometimes
interactions are missing. Cold start products or cold start users do
not have enough interactions for reliable measurement of their
interaction similarity so collaborative filtering methods fail to
generate recommendations.
In machine learning and natural language processing, a topic model is a type of statistical model for
discovering the abstract "topics" that occur in a collection of
documents. Topic modeling is a frequently used text-mining tool for
discovery of hidden semantic structures in a text body. Intuitively,
given that a document is about a particular topic, one would expect
particular words to appear in the document more or less frequently:
"dog" and "bone" will appear more often in documents about dogs, "cat"
and "meow" will appear in documents about cats, and "the" and "is" will
appear equally in both.
I used Latent Drichillet
Allocation(LDA) to find abstract articles from document, the document i
used was of news articles.Others used Word2Vec,Doc2Vec,Glove .
LDA
LDA
is an example of topic model and is used to classify text in a document
to a particular topic. It builds a topic per document model and words
per topic model, modeled as Dirichlet distributions.
Word2Vec
Word2vec
is a two-layer neural net that processes text. Its input is a text
corpus and its output is a set of vectors: feature vectors for words in
that corpus.The purpose and usefulness of Word2vec is to group
the vectors of similar words together in vectorspace. That is, it
detects similarities mathematically. Word2vec creates vectors that are
distributed numerical representations of word features, features such as
the context of individual words. It does so without human intervention.
Given enough data, usage and
contexts, Word2vec can make highly accurate guesses about a word’s
meaning based on past appearances.
GloVe
GloVe, coined from Global Vectors, is a model for distributed word representation. The model is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
Simple linear regression is useful for finding a relationship between two continuous variables. One is a predictor or independent variable and other is a response or dependent variable. It looks for a statistical relationship but not a deterministic relationship. The relationship between the two variables is said to be deterministic if one variable can be accurately expressed by the other. For example, using temperature in degree Celsius it is possible to accurately predict Fahrenheit. Statistical relationship is not accurate in determining the relationship between two variables. For example, the relationship between height and weight. With simple linear regression we want to model our data as follows: y = B0 + B1 * x This is a line where y is the output variable we want to predict, x is the input variable we know and B0 and B1 are coefficients we need to estimate. It also required us to understand the concept of gradient descent. Gradient Descent is the process of m...
Tuples We saw that lists and strings have many common properties, such as indexing and slicing operations. They are two examples of sequence data types (see Sequence Types — str, bytes, bytearray, list, tuple, range). Since Python is an evolving language, other sequence data types may be added. There is also another standard sequence data type: the tuple. A tuple consists of a number of values separated by commas, for instance: >>> t = 12345, 54321, 'hello!' >>> t[0] 12345 >>> t (12345, 54321, 'hello!') >>> # Tuples may be nested: ... u = t, (1, 2, 3, 4, 5) >>> u ((12345, 54321, 'hello!'), (1, 2, 3, 4, 5)) As you see, on output tuples are always enclosed in parentheses, so that nested tuples are interpreted correctly; they may be input with or without surrounding parentheses, although often parentheses are necessary anyway (if the tuple is part of a larger expression). Tuples have many uses. For example: (x, y) c...
Ropar's Accident data Our company was given Ropar's Accident data by the Government to analyze and submit insights from the data that could be helpful to the government for reducing the number of serious accidents. We analyzed the data by using Tableau with the help of pie charts, histograms, etc. We also made dashboards and stories which gave us a really good insight of the data. Convolutional Neural Networks We referred to the CMU's course on deep learning for understanding this concept.This lecture was taught by Bhiksha Raj Sir. CNNs, like neural networks, are made up of neurons with learnable weights and biases. Each neuron receives several inputs, takes a weighted sum over them, pass it through an activation function and responds with an output. Unlike neural networks, where the input is a vector, here the input is a multi-channeled image. The wholw network has a loss function. CNNs have wide applications in image and video rec...










Comments
Post a Comment