Week 6(19-23 August)
Continuing our ISB course on Unsupervised Learning, we completed 2 videos this week whose topics are as follows:
Introduction to Bayesian Learning
Bayes' Theorem: Bayes’
theorem describes how the conditional probability of an event or a
hypothesis can be computed using evidence and prior knowledge.
The Bayes’ theorem is given by:
P(θ|X)=P(X|θ)P(θ)P(X)
P(θ) -
Prior Probability is the probability of the hypothesis
θ
being true before applying the Bayes’ theorem. Prior represents the
beliefs that we have gained through past experience, which refers to
either common sense or an outcome of Bayes’ theorem for some past
observations.
P(X|θ)
- Likelihood is the conditional probability of the evidence given a hypothesis.
- Evidence term denotes the probability of evidence or data.
Types of distributions:
- Binomial distribution
- Bernoullie distribution
- Mutinomial distribution
- Poisson Distribution
Clustering
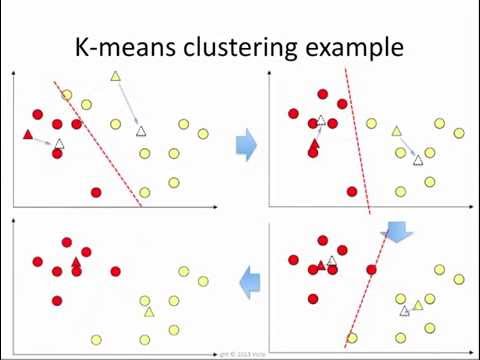
K-Means:
K-means
clustering is a type of unsupervised learning, which is used when you
have unlabeled data (i.e., data without defined categories or groups).
The goal of this algorithm is to find groups in the data, with the
number of groups represented by the variable K. The algorithm works iteratively to assign each data point to one of K groups based on the features that are provided. Data points are clustered based on feature similarity. The results of the K-means clustering algorithm are:
- The centroids of the K clusters, which can be used to label new data
- Labels for the training data (each data point is assigned to a single cluster)
Expectation Maximization:
The Expectation-Maximization (EM) algorithm is a way to find maximum-likelihood estimates for model parameters when
your data is incomplete, has missing data points, or has unobserved
(hidden) latent variables. It is an iterative way to approximate the
maximum likelihood function.
While maximum likelihood estimation can find the “best fit” model for a
set of data, it doesn’t work particularly well for incomplete data
sets. The more complex EM algorithm can find model parameters even if you have missing data. It
works by choosing random values for the missing data points, and using
those guesses to estimate a second set of data. The new values are used
to create a better guess for the first set, and the process continues
until the algorithm converges on a fixed point.
Session with Vikram sir
After
clearing all the concepts of EDA and Feature Engineering, we practised
on some datasets and then Vikram sir instructed us to find data sets
individually as work on them.
After submissions before the dealine, he evaluated our performance and made us aware of our mistakes and how we can improve our skills.
It proved to be very helpful as EDA and feature engineering are an essential part of machine learning without which model cannot be trained.

Comments
Post a Comment